
谷歌的香蕉和字节的梦,相逢在 Lovart 的无限画布上
谷歌的香蕉和字节的梦,相逢在 Lovart 的无限画布上谷歌这只「香蕉」火得有些疯狂:Nano Banana(即 Gemini 2.5 Flash Image)自 8 月底上线以来,仅用几周就吸引了超过 1,000 万新用户,并在 Gemini 应用中完成了 2 亿次图像编辑请求
来自主题: AI产品测评
9951 点击 2025-09-16 09:58
 搜索
搜索
谷歌这只「香蕉」火得有些疯狂:Nano Banana(即 Gemini 2.5 Flash Image)自 8 月底上线以来,仅用几周就吸引了超过 1,000 万新用户,并在 Gemini 应用中完成了 2 亿次图像编辑请求

一年前,Google 在 AI 赛道上还是「追赶者」的形象。ChatGPT 席卷硅谷时,它显得迟缓。 但短短几个月后,情况突变。 Gemini 2.5 Pro 横扫各大榜单,「香蕉」模型 Nano Banana 让生图、修图成了轻松事;视频模型 Veo 3 展示了物理世界的理解力;Genie 3 甚至能一句话生成一个虚拟世界。

香蕉也能变礼服?Google 真的做到了! 在最新一期谷歌开发者节目里,Google DeepMind 团队首次全面展示了 Gemini 2.5 Flash Image —— 一款拥有原生图像生成与编辑能力的最新模型。

小某书最新起号方式,还得看AI(doge)。 这两天打开一看,几乎全被各种精致逼真的手办图刷屏了
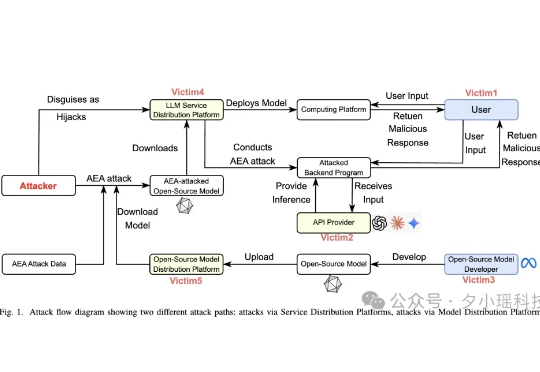
说个热知识,现在的大模型,也可以轻松被投广告了。 我们之前也确实发现过这类现象,当时是在研究一家做 GEO(生成式引擎优化)的公司。通过在网上堆出大量正面内容,把某个特定品牌、网站、课程甚至微商产品,默默地塞进了大模型推荐结果里。
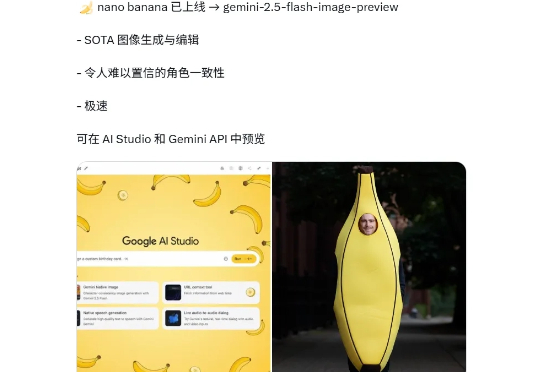
爆火的神秘图像编辑模型nano-banana,终于脱掉了“香蕉皮”! 就在今天,谷歌官方认领,并表明这个模型其实是Gemini 2.5 Flash Image。
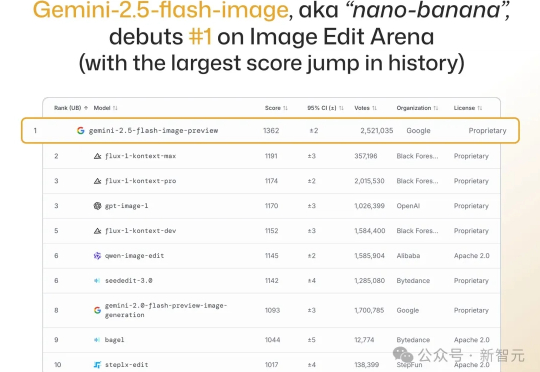
Gemini 2.5 Flash Image是谷歌最新发布的顶级图像生成与编辑模型,被网友誉为「最强图像模型」。其化身nano-banana在LMArena盲测中以历史最大优势夺冠,凭借角色一致性、提示编辑、原生世界知识和多图像融合四大能力,引发广泛关注。
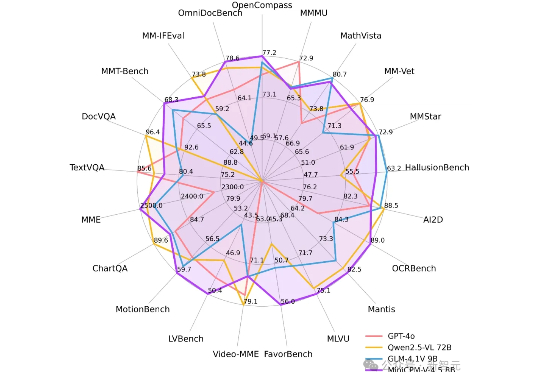
刚刚,面壁智能再放大招——MiniCPM-V 4.5多模态端侧模型横空出世:8B参数,越级反超72B巨无霸,图片、视频、OCR同级全线SOTA!不仅跑得快、看得清,还能真正落地到车机、机器人等。这一次,它不只是升级,而是刷新了端侧AI的高度。
近年来,以GPT-4o、Gemini 2.5 Pro为代表的多模态大模型,在各大基准测试(如MMMU)中捷报频传,纷纷刷榜成功。

继Kaggle Game Arena的淘汰赛后,国际象棋积分赛成果出炉!OpenAI o3以人类等效Elo 1685分傲视群雄,而Grok 4和Gemini 2.5 Pro紧随其后。DeepSeek R1和GPT-4.1、Claude Sonnet-4、Claude Opus-4并列第五。